반응형
파이썬 기초
test01.py
# 1. 파이썬 기초
# 변수 저장 출력
a = 1
b = 2
c = a + b
d = a * b
print(a)
print(b)
print(c)
print(d)
# 문자 출력
print('Hello World!') # 문자열은 '' , "" 로 감싸기
print('makit "code" lab') # ""는 ''안에 출력
print("she's gone") # ''는 ""안에 출력
# 변수와 문자 출력
a = 10
b = 20
c = a + b
print('a의 값은', a) # 변수와 문자를 구분할 때 , 사용
print('b의 값은', b)
print('a와 b의 합은', c)
# 정수와 문자 연산
a = 10
b = 'makit '
print(a * 3) # 10 곱하기 3
print(b * 3) # makit 3번 출력
test02.py
# 1. 파이썬 기초
# 리스트
a = [38, 22, 94, 11234, 43523]
print(a)
print(a[0])
# 리스트 문자
b = ['makit', '우진', '시은']
print(b)
print(b[0])
print(b[1])
print(b[2])
# 리스트 정수와 문자 출력
c = [ 'james', 26, 175.4, True]
print(c)
d = ['메이킷', '우진','제임스', '시은']
print(d[0:2])
print(d[0], d[1])
# extend() 함수 사용하여 리스트 이어붙이기
a = ['우진', '시은']
b = ['메이킷', '소피아', '하워드']
a.extend(b)
print(a)
print(b)
c = ['우진', '시은']
d = ['메이킷', '소피아', '하워드']
d.extend(c)
print(d)
print(c)
test03.py
import numpy as np => numpy 라이브러리 불러오기
a = np.array([[1, 2, 3],[4, 5, 6]])
print('안바꾼거 : \n', a)
a_transpose = np.transpose(a) => 행렬 바꿔주는 함수
print('바꾼거 :\n', a_transpose)
# 바꾼거 :
# [[1 4]
# [2 5]
# [3 6]]
a_reshape = np.reshape(a, (3,2)) => 행렬 바꿔주는 함수
print('reshape 바꾼거 : \n', a_reshape)
# reshape 바꾼거 :
# [[1 2]
# [3 4]
# [5 6]]
# transpose()와 reshape()의 차이점:
# transpsee()는 데이터의 순서대로 바뀜
# reshape()은 데이터를 변형해서 바뀜딥러닝 다층 퍼셉트론 실습
연속되는 수 예측하기
# 1. 데이터
import numpy as np
x = np.array([1, 2, 3])
y = np.array([1, 2, 3])
# 2. 모델구성
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(10, input_dim=1)) # 입력층
model.add(Dense(5)) # 히든레이어
model.add(Dense(7)) # 히든레이어
model.add(Dense(5)) # 히든레이어
model.add(Dense(1)) # 출력층
# 3. 컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
model.fit(x, y, epochs=1000)
# 4. 예측, 평가
loss = model.evaluate(x, y)
print('loss : ', loss) # loss : 3.1487465412816107e-10
result = model.predict([4]) # 4의 예측값 : 3.999965
print('4의 예측값', result)
연속되지 않는 수 예측하기
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 1. 데이터
x = np.array([1, 2, 3, 5, 4])
y = np.array([1, 2, 3, 4, 5])
# 2. 모델구성
model = Sequential()
model.add(Dense(64, input_dim=1)) # 입력층
model.add(Dense(128)) # 히든레이어
model.add(Dense(256)) # 히든레이어
model.add(Dense(128)) # 히든레이어
model.add(Dense(64)) # 히든레이어
model.add(Dense(1)) # 출력층
# 3. 컴파일, 훈련
model.compile(loss='mse' , optimizer='adam') # w값이 (-)일때 'mae' 사용
model.fit(x, y, epochs=50, batch_size=32)
# 4. 예측, 평가
loss = model.evaluate(x, y) # loss : 0.39812880754470825
print('loss : ', loss)
result = model.predict([6])
print('6의 예측값 : ', result) # 6의 예측값 : [[6.005654]]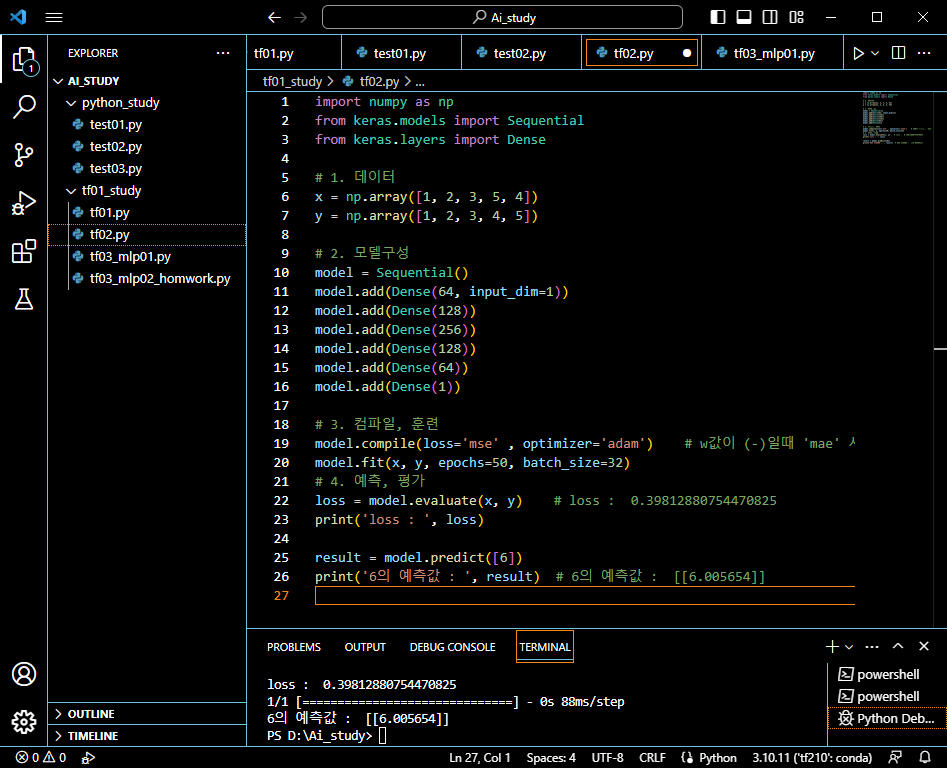
2행 예측
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 1. 데이터
x = np.array([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[1, 2, 1, 1, 2, 1.1, 1.2, 1.4, 1.5, 1.6]])
y = np.array([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
print(x.shape) # (2, 10)
print(y.shape) # (10,)
x = x.transpose()
# x = x.T
print(x.shape) # (10, 2)
# 2. 모델구성
model = Sequential()
model.add(Dense(64, input_dim=2)) # 입력층
model.add(Dense(128)) # 히든레이어
model.add(Dense(256)) # 히든레이어
model.add(Dense(128)) # 히든레이어
model.add(Dense(64)) # 히든레이어
model.add(Dense(1)) # 출력층
# 3. 컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
model.fit(x, y, epochs=500, batch_size=16)
# 4. 평가, 예측
loss = model.evaluate(x, y)
print('loss : ', loss) # loss : 6.639311496414724e-12
result = model.predict([[10, 1.6]])
print('[10]과 [1.6]의 예측값 : ', result) # [10]과 [1.6]의 예측값 : [[20.]]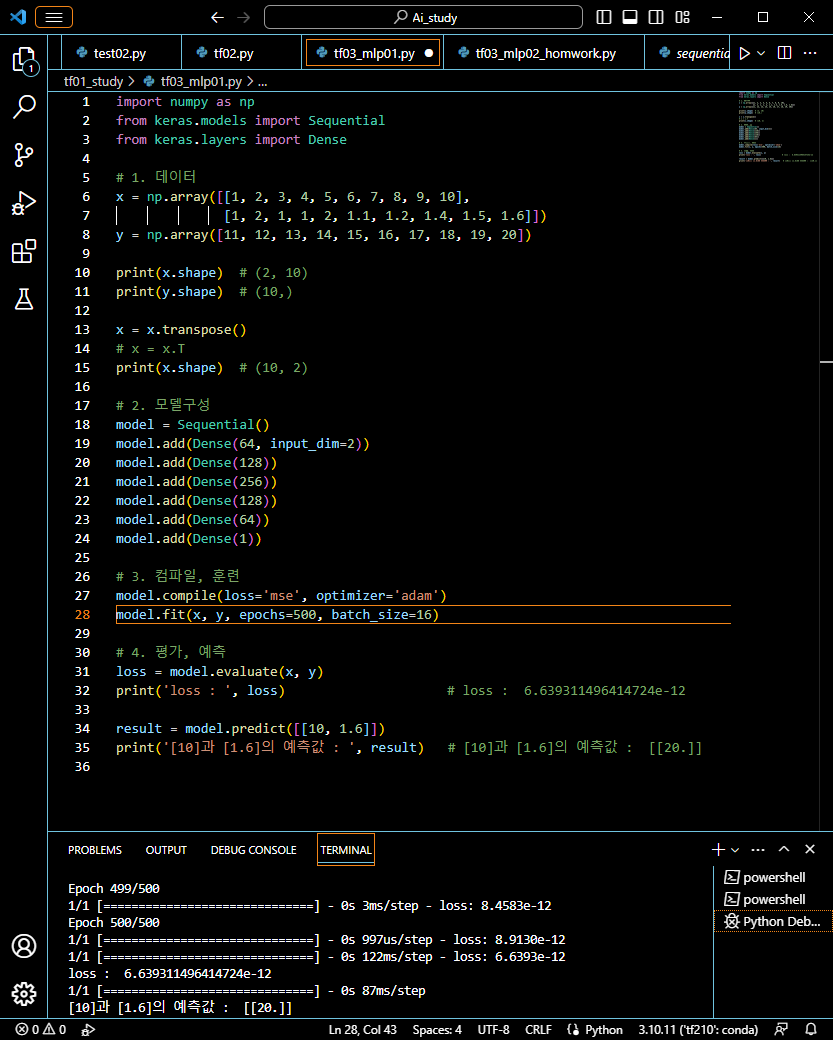
과제: 3행 예측
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 1. 데이터
x = np.array([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[1, 2, 1, 1, 2, 1.1, 1.2, 1.4, 1.5, 1.6],
[10, 9, 8, 7, 6, 5, 4, 3 ,2 ,1]])
y = np.array([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
# 미션:
# 모델구성부터 평가예측까지 완성하시오.
# 예측값은 [[10, 1.6, 1]] 20 나오도록.
print(x.shape) # (2, 10)
print(y.shape) # (10,)
x = x.transpose()
# x = x.T
print(x.shape) # (10, 2)
# 2. 모델구성
model = Sequential()
model.add(Dense(64, input_dim=3)) # 입력층
model.add(Dense(128)) # 히든레이어
model.add(Dense(256)) # 히든레이어
model.add(Dense(128)) # 히든레이어
model.add(Dense(64)) # 히든레이어
model.add(Dense(1)) # 출력층
# 3. 컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
model.fit(x, y, epochs=500, batch_size=16)
# 4. 평가, 예측
loss = model.evaluate(x, y)
print('loss : ', loss) # loss : 1.1186785005279365e-11
result = model.predict([[10, 1.6, 1]])
print('[10]과 [1.6]과 [1]의 예측값 : ', result)
# [10]과 [1.6]과 [1]의 예측값 : [[20.000004]]
반응형
'[네이버클라우드] AIaaS 개발자 과정 > AI' 카테고리의 다른 글
| [네이버클라우드캠프] 2023.5.9 AI(2) - 실습 2 (0) | 2023.05.09 |
|---|---|
| [네이버클라우드캠프] 2023.5.9 AI(1) - 실습 1 (0) | 2023.05.09 |
| [네이버클라우드캠프] 2023.5.8 AI - 인공지능 개념 정리 (추가) (0) | 2023.05.08 |
| [네이버클라우드캠프] 2023.5.8 AI(1) - Anaconda, Visual Studio Code 설치 (0) | 2023.05.08 |